Although microservice architectures are flexible compared to monolithic architectures, aggregating data from decoupled services is a big challenge in microservice architectures. This problem can be solved by using GraphQL which is an open-source data query and manipulation language. GraphQL provides flexibility and efficiency in client-server architectures. In this blog post, a solution to the data aggregation problem will be shown by using the GraphQL aggregation layer on RESTful microservices.
The main advantage of GraphQL is that it aggregates data from different data stores by using an endpoint. Besides that, GraphQL fetches only data that clients need. In this way, it solves an over-fetching problem, avoiding fetching too much data that clients do not need.
Definition of the Sample Architecture
The GraphQL aggregation layer is used to get requests from outside like mobile/web clients. This layer is also responsible for handling data aggregations. Apart from the GraphQL Aggregation Layer, there are three entity microservices (Student, Classroom, Teacher) which have their own database, and entities that are defined and exposed in these services. There is one to one relationship between Teacher and Classroom. And, there is one to many relationship between Student and Classroom. The relations between these entities are shown in the entity diagram below.
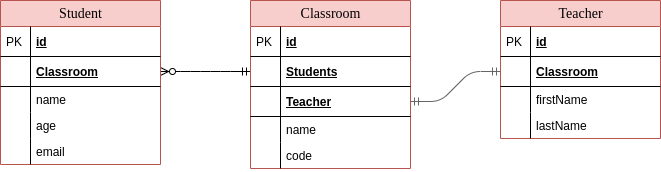
The GraphQL aggregation layer calls these entity services and combines objects to prepare responses for the clients. The different schemas which correspond to each of the entities are defined in the GraphQL aggregation layer as follows:
|
type Student { |
type Teacher { firstName: String! |
type Teacher { firstName: String! |
To visualize it better, there is a topology diagram below. The GraphQL Aggregation Layer compensates requests; based on these requests, entity services with REST are called and receive needed data from the entity service, then do aggregation.

In the microservice architecture, one main problem is the Call Complexity (just like memory and time complexities like O(N)). In order to reduce the Call Complexity, the GraphQL data aggregation layer should not cause the n+1 problem.
What is the n+1 problem in a nutshell?
Let's give an example to understand the n+1 problem.
Let say we have two entities like Classroom and Student. There is a many-to-one relationship between these two entities. We need to retrieve students using their classroom_ids. We first send a query to the Classroom table to get a list of all classroom_ids:
SELECT * FROM CLASSROOM;
And then, we send queries to the Student table with each classroom_id one by one:
SELECT * FROM STUDENT WHERE CLASSROOM_ID = 1
SELECT * FROM STUDENT WHERE CLASSROOM_ID = 2
We see the n+1 problem here.
How the n+1 problem is solved in GraphQL: Using Data Loaders
There are two ways to solve the n+1 problem. First way is using the INNER JOIN. However, since there are three different databases per microservice, this way is not applicable. The second way is to use the “IN” operator. So, there is only an option for this architecture.
For using the IN operator, we need batch processing. It allows us to group related ids into a batch and submit them with one call to the entity microservices. And, entity services should get this one call and fetch rows in the database with the IN operator. In this way, the n+1 problem is addressed.
The DataLoader provides us with a batching feature. Let’s fetch all students with the code block below. getStudents method returns a list of all Student objects.
getStudents: () => {
return fetch(`http://localhost:8080/students`).then(function (response) {
if (response.ok) {
return response.json()
} else {
return Promise.reject(response)
}
}
},
The resolver below is the representation of the Student Type that is defined in the schema. As you see, the classroom object is also needed, when the student object is fetched. The classroom object is loaded by loaderStudent.
Student: {
id: (student, _args) => student.id,
classroom: (student, _args, { loaderStudent }) => {
return loaderStudent.classrooms.load(student.classroomId);
}
}, In the classroom microservice, there is an endpoint: "/ classroom / find-by-ids". This endpoint retrieves rows in the database with IN operator. The loaderStudent batches classroom_ids and sends a request to the "/ classroom / find-by-ids" endpoint with classroom_ids.
const loaderStudent = {
classrooms: new DataLoader(async ids => {
const dto = {
ids: ids
}
const rows = await fetch(`http://localhost:8081/classroom/find-by-ids`,
{ method: 'POST', body: JSON.stringify(dto), headers: { 'Content-Type': 'application/json' } }
).then(res => res.json())
const lookup = rows.reduce((acc, row) => {
acc[row.id] = row;
return acc;
}, {});
return ids.map(id => lookup[id] || null);
}, { cache: true })
}
Generated Query by Classroom Microservice:
select classroom0_.id as id1_0_, classroom0_.code as code2_0_, classroom0_.name as name3_0_, classroom0_.teacher_id as teacher_4_0_ from classroom classroom0_ where classroom0_.id in (? , ? , ?)
Optional Caching
Although the data loaders solve the n+1 problem, there should still be ways to improve performance, i.e. Caching.
DataLoader has the optional in-memory caching feature. If optional caching is activated, the GraphQL aggregation layer returns a response without sending a request to the entity services. If we add the following line to the dataLoaders that are defined in the GraphQL aggregation layer, caching is activated.
}, { cache: true })
Conclusion
In this blog post, an efficient solution of the data aggregation problem is explained. In our personal opinion, using the GraphQL aggregation layer on REST microservices is a good approach. This approach solves the n+1 problem and caching in DataLoader can improve performance for data retrieval in microservice architectures.
Thanks to:
Project Link : https://github.com/kloia/graphql-aggregation
Resources: