Once upon a time, CSI wasn’t an option for us. So we went with another storage solution and something happened. Its huge horns were rising beyond the horizon… It was Longhorn and its “Actual size”…
Just joking…
As kloia SRE team we want to talk about an incident that occured with Longhorn on one of our projects. TLDR; Longhorn volumes' actual size was getting larger and larger and we solved it by enabling recurrent snapshots.
Environment
We had an RKE2 cluster with 3 worker nodes. We were using Longhorn as our storage provider for workloads. Each node had several physical disks attached to them and an LVM configuration was used for scalability.
Normally we would use CSI for storage provisioning but this wasn’t an option because we didn’t have access to vSphere API. So we chose Longhorn for this job.
.webp?quality=low&width=770&height=518&name=Asset_7@3x%20(1).webp)
Environment Schema
Incident
As Prometheus wrote new monitoring data at every scraping duration Longhorn volumes’ actual size was getting larger. Even though Prometheus was removing old wal files (Prometheus retention policy was in place) Longhorn volumes’ actual size wasn’t shrinking. At one point it exceeded the given PVC size and started to fill up nodes' disk space critically. Nodes were about to be unavailable because of the disk pressure.
How did we hear about this?
Zabbix was actively monitoring worker nodes’ disk usage and it alerted our SRE team at defined thresholds (80% - 95%).
Why was the Longhorn Actual Size getting larger?
Prometheus was writing all over the place randomly, it was using different blocks in our block devices. So the block device couldn’t know which parts were not used anymore. Also there weren't any features available for space reclamation like fstrim.
Prometheus PVC size (100GB) was large (actually this was the expected PVC size). So Longhorn filled up our nodes’ disk spaces pretty quickly.
What went well?
- We haven’t experienced any downtime.
- Prometheus' data wasn’t critical.
- Our node disk sizes weren’t homogeneous and Longhorn replica rebalancing feature works well.
- LVM configuration was in place for scalability, so adding more disks was an option if necessary.
Solution
First, giving less PVC size could be better to slow down disk usage if you can. But our expected PVC size for Prometheus was already 100GB minimum.
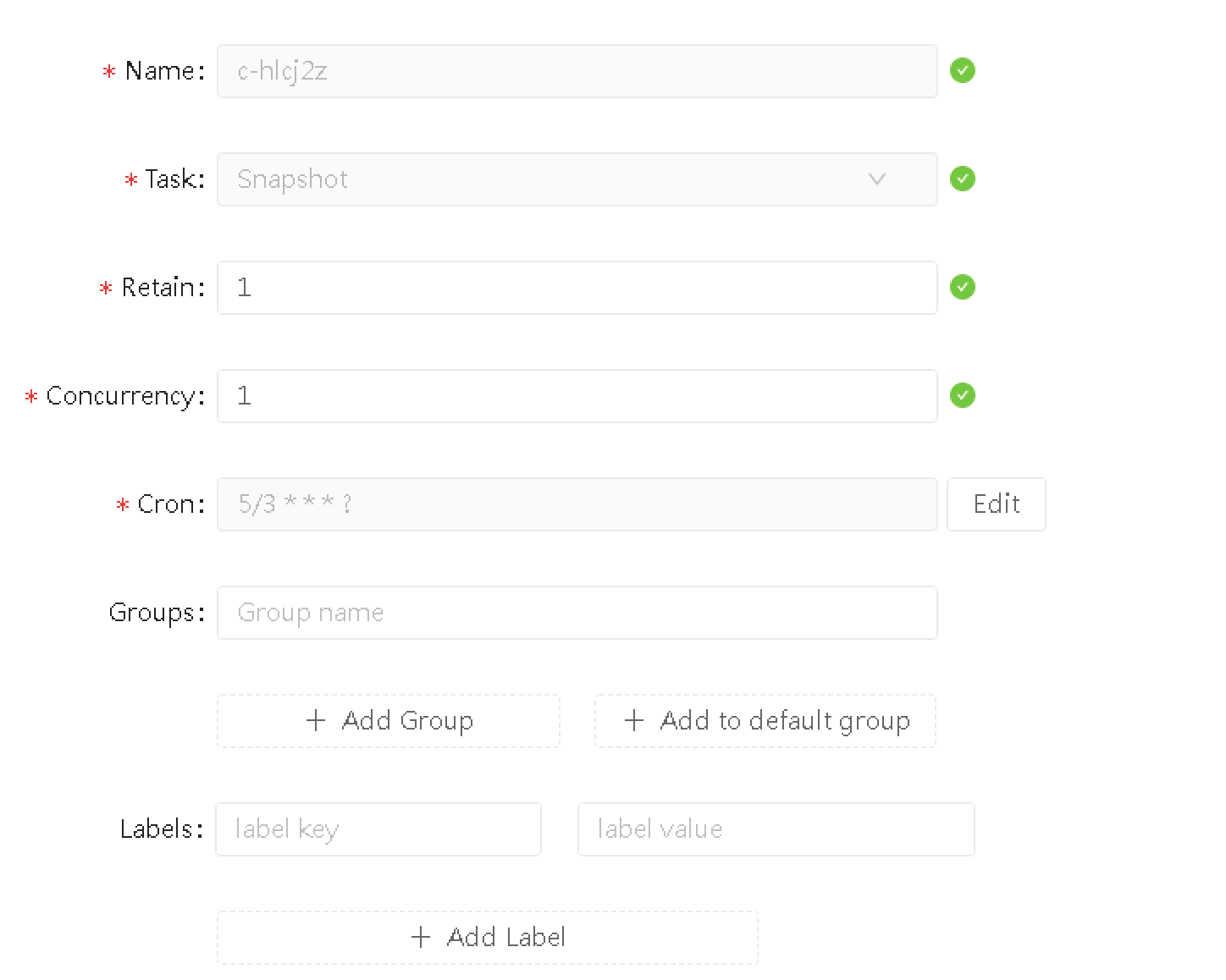
We enabled recurrent snapshots for Prometheus Longhorn volume. We set concurrent snapshot count to “1”. So everyday at 00:00 a.m Longhorn took a new snapshot and removed the old one. Everytime Longhorn did that recurrent snapshot, it merged the old snapshot and the new one together, reducing the actual size of Longhorn volume like the Linux fstrim command.